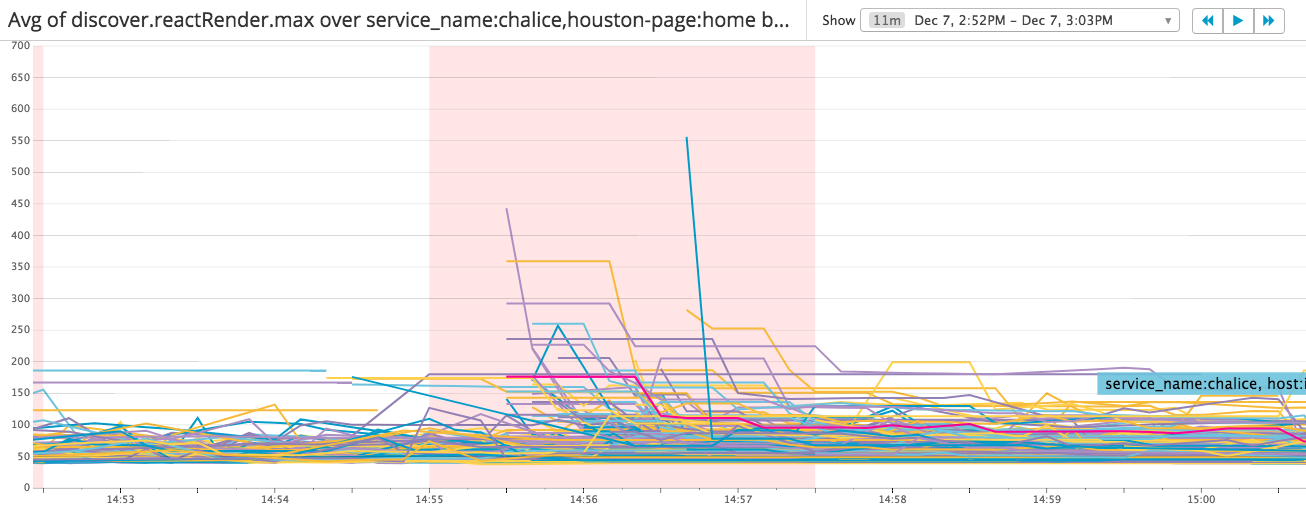
What? Connection reset by peer?
We are running Node.js web services behind AWS Classic Load Balancer. I noticed that many 502 errors after I migrate AWS Classic Load Balancer to Application Load Balancer. In order to understand what happened, I added Nginx in front of the Node.js web server, and then found that there are more than 100 ‘connection reset’ errors everyday in Nginx logs.
Here are some example logs:
2017/11/12 06:11:15 [error] 7#7: *2904 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost"
2017/11/12 06:11:27 [error] 7#7: *2950 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost"
2017/11/12 06:11:31 [error] 7#7: *2962 upstream prematurely closed connection while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost"
2017/11/12 06:11:44 [error] 7#7: *3005 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost"
2017/11/12 06:11:47 [error] 7#7: *3012 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 172.18.0.1, server: localhost, request: "GET /_healthcheck HTTP/1.1", upstream: "http://172.18.0.2:8000/_healthcheck", host: "localhost"
Analyzing the errors
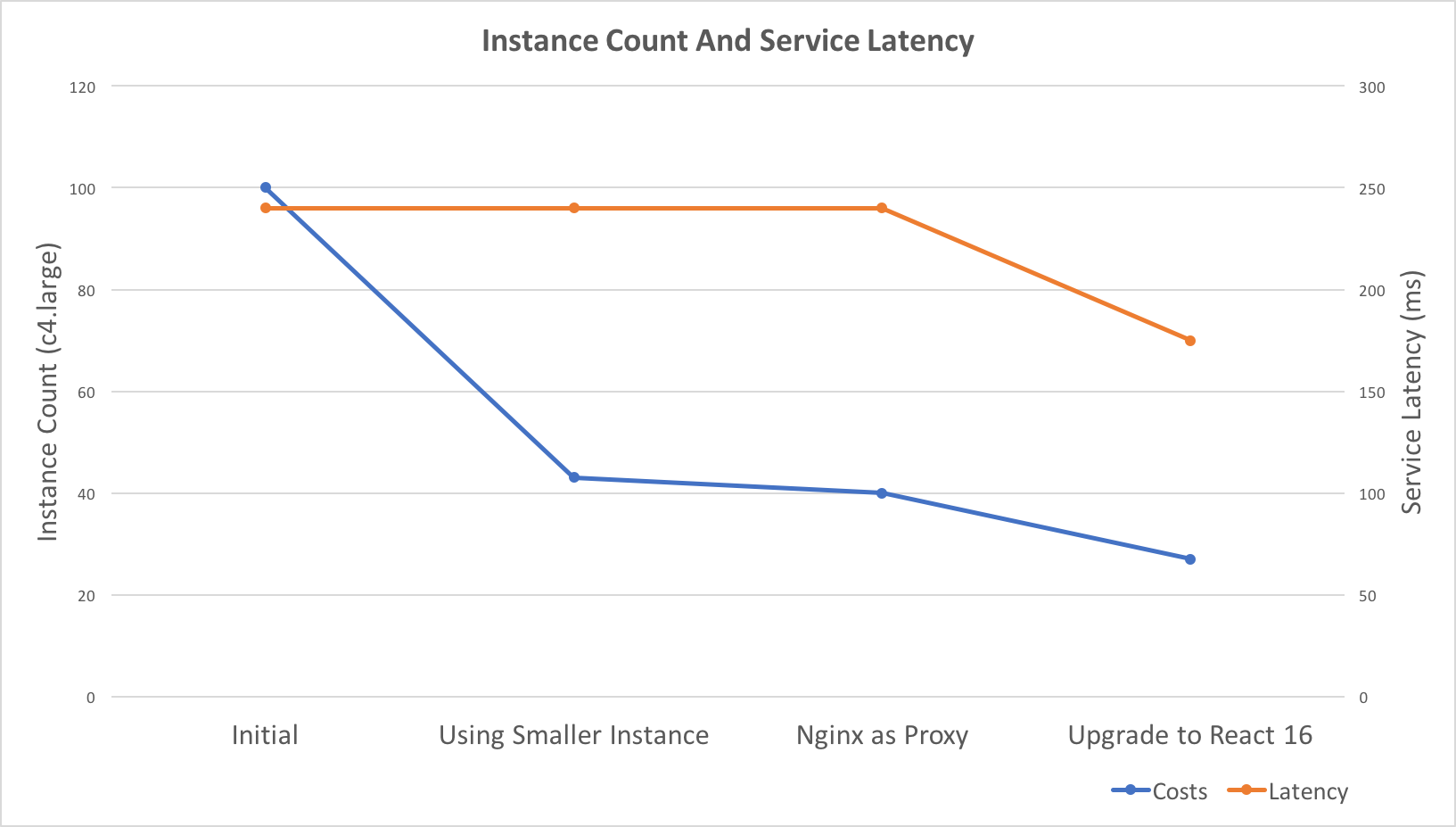
The number of errors was increased after I migrate Classic LB to Application LB, and one of the differences between them is Classic LB is using pre-connected connections, and Application LB only using Http/1.1 Keep-Alive feature.
From the documentation of AWS Load Balancer:
Possible causes:
- The load balancer received a TCP RST from the target when attempting to establish a connection.
- The target closed the connection with a TCP RST or a TCP FIN while the load balancer had an outstanding request to the target.
- The target response is malformed or contains HTTP headers that are not valid.
- A new target group was used but no targets have passed an initial health check yet. A target must pass one health check to be considered healthy
Continue reading “Analyze ‘Connection reset’ error in Nginx upstream with keep-alive enabled”