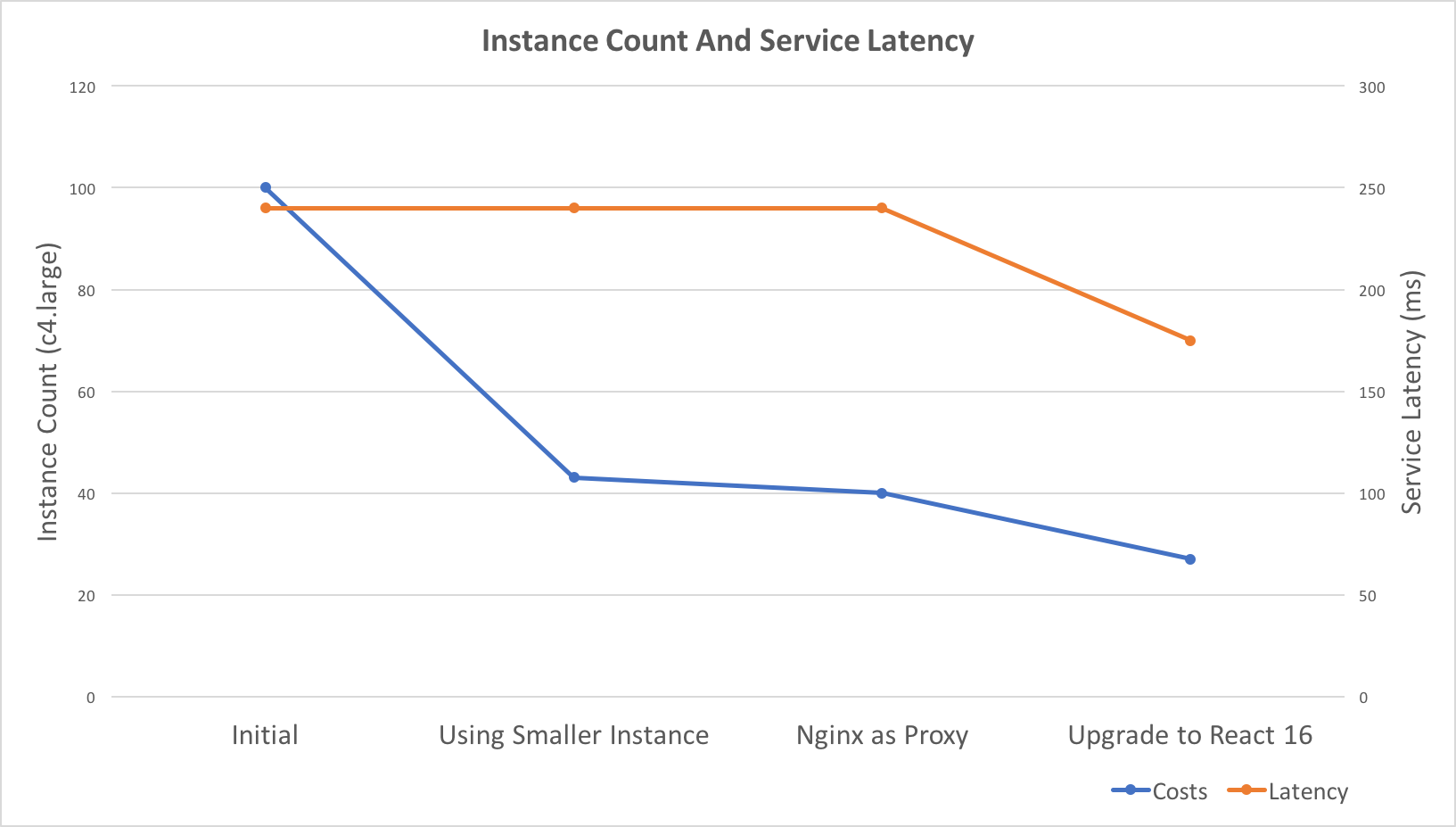
Recently, I did some work related to auto-scaling and performance tuning. As a result, the costs reduced to 27% and service latency improved 25%.
Takeaways
- React Server Side Render performs not good under Nodejs Cluster, consider using a reverse proxy, e.g. Nginx
- React V16 Server Side Render performs much faster than V15, 40% in our case
- Use smaller instances to get better scaling granularity if possible, e.g. change C4.2xLarge to C4.Large
- AWS t2.large performs 3 times slower than C4.large on React Server Side Render
- AWS Lambda performs 3 times slower than C4.large on React Server Side Render
- There’s a race condition in Nginx http upstream keepalive module which generates 502 Bad Gateway errors (104 connection reset by peer)
Background
Here’s the background of the service before optimization:
- Serving 6000 requests per minute
- Using AWS Classic Load Balancer
- Running 25 C3.2xLarge EC2 instances which have 8-core CPU on each instance
- Using PM2 as the Process Manager and the Cluster Manager
- Written in Nodejs and using React 15 server-side render
Continue reading “Metrics Driven Development – What I did to reduce AWS EC2 costs to 27% and improve 25% in latency”