问题背景介绍
最近的项目需要进行很多的文件处理,因此就有了大量的IO操作。有的地方是先解密,再加密,有的是压缩,加密,再签名,最主要的是所有的非加密文件都需要安全删除,先填充一遍0,再把文件删除。
初始解决方案和问题
开始时我们使用文件来存储处理过程中的临时数据,以文件更换密码为例,需要进行如下处理:
- 解密原来的加密文件,写到一个临时文件
- 读取解密的临时文件,加密写到最终文件
- 将临时文件填充0,并删除
示例代码如下:
FileEncryptor.decrypt(originalEncryptedFile, tempFile); FileEncryptor.encrypt(tempFile, resultEncryptedFile); FileEraser.safeErase(tempFile);
这个过程中的IO操作如下图所示:
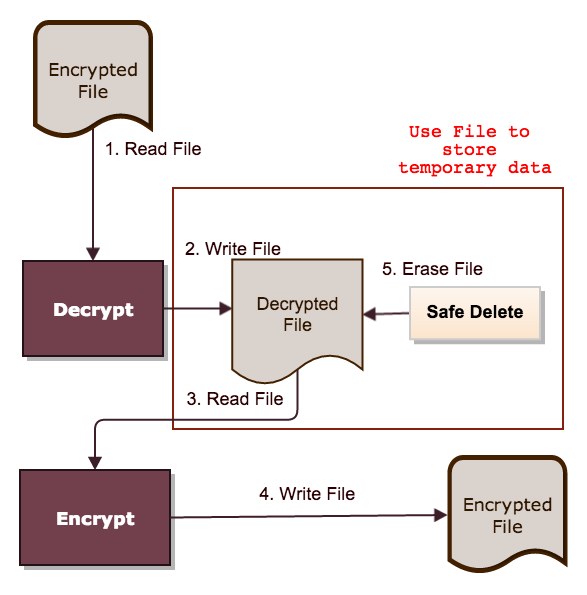
整个过程有2次文件读取,3次写入操作,但其实红框内的部分并不是必须的,就是说有2/3的写操作和1/2的读操作都是浪费的。考虑到IO操作的高成本,我第一个想法是:能不能去掉临时文件部分的IO操作呢?直接把解密后的数据再加密写到最终文件里就可以减少3/5左右的IO操作。
减少IO的方案分析
因为文件大小不确定,所以直接把整个文件全部读入内存是不行的。那就只能按数据块一批批的处理,于是问题就成了这些文件处理是不是可以按块进行。好,问题明确了,那就对这些文件操作逐一进行分析:
- AES加解密 (http://en.wikipedia.org/wiki/Advanced_Encryption_Standard)AES加解密是按数据块来处理的,每次处理的数据块是128bits, 也就是16个字节,如果最后的数据不足16个字节就通过padding进行补齐
- PGP签名我们使用BouncyCastle来进行PGP签名,整体过程也是对文件进行按块处理
- Zip (http://en.wikipedia.org/wiki/Zip_(file_format))zip文件的格式在wikipedia里有详细的介绍,这里大概的总结一下: 在Zip文件的末尾有Central directory file header, 里面记录了zip文件有多少个文件, 以及每个文件的名称, 原始大小, 压缩后的大小以及对应的local file header所处的位置。 在对应的local file header处, 同样有字段来存储原始大小, 压缩后的大小, 但可以为0。 我个人的理解是zip文件设计初也是考虑到写到外部存储的性能差, 所以也是为了方便一次性写入, 才有的两层file header的设计。 在这一点, zip文件的格式又和pdf的格式很相似, 都是在文件尾存放指向各个entry的信息
确定这三种操作都支持按块处理文件后,就可以开始动手试一下了.
引入流式文件处理减少IO
还是以解密加密为例,使用内存作为缓存后的流程如下图:
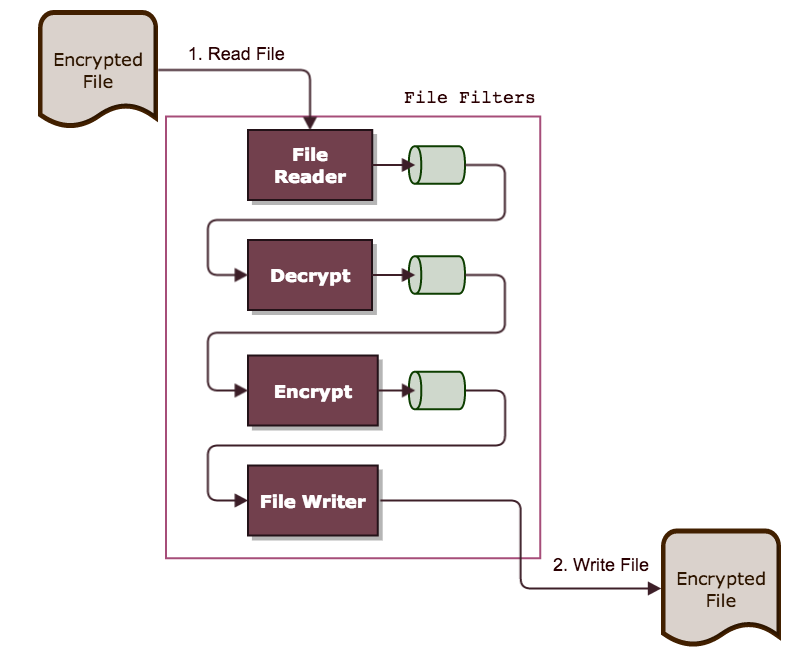 中间大框中的部分类似于过滤器,在读取文件内容后,经过一系列的过滤操作,生成最终文件。过滤器中的过滤模块可以任意组合,比如上图是,读取文件->解密->加密->写入文件,可以写为:
中间大框中的部分类似于过滤器,在读取文件内容后,经过一系列的过滤操作,生成最终文件。过滤器中的过滤模块可以任意组合,比如上图是,读取文件->解密->加密->写入文件,可以写为:
int bufSize = 1024 * 8;
new FileProcessFilters()
.withFilter(new FileInputFilter(bufSize, new File("LibreOffice_4.tgz.encrypted")))
.withFilter(new AesDecryptionFilter(bufSize, oldPassword))
.withFilter(new AesEncryptionFilter(bufSize, newPassword))
.withFilter(new FileOutputFilter(new File("LibreOffice_4.tgz.encrypted.updated")))
.filter();
也可以很容易的根据需要改成:压缩文件(或者目录,多个文件)->加密->签名->写入文件:
int bufSize = 1024 * 8;
new FileProcessFilters()
.withFilter(new InputFileZipFilter(bufSize, new File("LibreOffice_4")))
.withFilter(new AesEncryptionFilter(bufSize, password))
.withFilter(new PGPSignatureFilter(bufSize, certificate))
.withFilter(new FileOutputFilter(new File("LibreOffice_4.zip.encrypted.signed")))
.filter();
FileProcessFilters类的主要逻辑是:从输入文件中不断读取一定大小的数据块,对每个数据块执行所有的过滤操作,一直到文件结束。示例代码如下:
public class FileProcessFilters {
private List filters = new ArrayList<>();
public void filter() {
byte[] in = null;
boolean finished = false;
while (!finished) {
for (FileProcessFilter filter : filters) {
in = filter.filter(in);
if (!finished) {
finished = filter.getFinished();
}
//restart process from the first filter,
//because no data generated in current filter
if (in.length == 0) {
break;
}
}
}
in = null;
for (FileProcessFilter filter : filters) {
in = filter.finish(in);
}
}
private FileProcessFilters withFilter(FileProcessFilter filter) {
filters.add(filter);
return this;
}
}
现在以zip为例演示如何进行filter,为了简单起见,这里并没有处理多层文件夹的情况:
private static class InputFileZipFilter extends FileProcessFilter {
private final Iterator iterator;
private InputStream fileInputStream;
private final ZipOutputStream zipOutputStream;
public InputFileZipFilter(File file, int bufSize)
throws FileNotFoundException {
super(bufSize);
zipOutputStream = new ZipOutputStream(output);
if (file.isDirectory()) {
iterator = asList(file.listFiles()).iterator();
}else{
iterator = asList(file).iterator();
}
}
public byte[] filter(byte[] in) throws IOException {
output.reset();
if (fileInputStream == null) {
if (iterator.hasNext()) {
File file = iterator.next();
fileInputStream = new FileInputStream(file);
zipOutputStream.putNextEntry(new ZipEntry(file.getName()));
} else {
setFinished(true);
zipOutputStream.closeEntry();
zipOutputStream.close();
return output.toByteArray();
}
}
int readCount = fileInputStream.read(buf);
if (readCount <= 0) {
fileInputStream.close();
fileInputStream = null;
return new byte[0];
}
if (readCount < buf.length) {
fileInputStream.close();
fileInputStream = null;
}
zipOutputStream.write(buf, 0, readCount);
return output.toByteArray();
}
@Override
public byte[] finish(byte[] in) throws IOException, EncryptionException {
return new byte[0];
}
}
实现Filter时,最主要的一点是注意,每次操作的只是一部分数据,所以需要自己记住状态,这一点我感觉很像使用Epoll时,处理事件响应的方式。以Aes加密为例,初始状态下需要初始化IV, 每次加密部分数据时,调用cipher.update()方法, 最终结束时调用cipher.doFinal()方法。
好了,就这样换了文件的处理方式后,我们以大约原来2/5的IO操作达到了同样的结果。
后记
- 在整理出文件处理流程后,我就在反思是什么启发我用这种方式来解决问题,这时候意识到是Nginx设计结构的影响:系统由众多的模块组成,每个模块只做一件事情,使用者通过配置文件选择需要的模块对需要的功能进行定制,并且处于性能的考虑,尽量减少内存复制。在这里,减少内存复制变成了减少硬盘访问,但是也可以再更进一步,使前一步的输出和下一步的输入使用同一块内存,来减少内存复制的成本,但同时也会更大的提高代码复杂度。
- 文件格式的设计上,zip和pdf采用了很类似的结构,都是为了便于更新内容时快速的更新文件,进行了空间换取时间的设计